

The Pseudo Random String Generator (or PseudoRandomStringGenerator)
is a
software to generate
pseudorandom sequences of characters. The application
provides a
simple graphical user interface, where you can define the alphabet
and
the length of the string to be
generated. You
can
choose the alphabet for the string either explicitly (character by
character, all Unicode characters are valid), or use
preconfigured alphabets like all Latin lowercase letters, all Latin
uppercase letters,
all numbers, the most common special characters and combinations of
these.
Why building a new random number generator, aren't there already
enough of them out there? While this is true in terms of quantity, I
found it necessary to develop my own special tailored application. Most
existing generators were developed for experts (e.g. scientific
software, modules to integrate into
other software), or they are online applications. Also, there are many
suspicious closed source generators, which I wouldn't trust. My goal is
to deliver
a simple tool with a straightforward user interface, so that anybody
should be able to use it. Therefore, it is also free and open source.
Additionally, my software is
working offline, to be independent from the internet and to avoid
vulnerabilities caused by sending the output across the internet.
The current version produces cryptographically secure pseudorandom
sequences
of characters. You can expect local
randomness, even distribution and a cryptographically strong generation
process. Roughly this means, that it is computationally hard to predict
next characters of a
sequence, even if an attacker could read the past output sequence and
knows parts of the inner state of the computer, but it may be possible.
The software uses the Java Class SecureRandom
to be able to deliver cryptographically secure pseudorandom sequences.
Therefore, the output of this class complies with the statistical
random number generator tests as specified in the FIPS 140-2,
Security
Requirements for Cryptographic Modules, section 4.9.1. and
additionally with RFC 1750: Randomness Recommendations
for Security ("must produce non-deterministic output").
I can not guarantee, that my software still meets the above
requirements, but from a software engineering point of view, I don't
see any reason, why the output
of my implementation could be any weaker than the output of the
original Java class. As the software is free and open source, you are
always
welcome to verify, comment and contribute.
If you are interested in more information about some of the maybe
a
bit too technical
phrases above, keep reading. Otherwise you may want to go directly to
the
Download section, at
the
bottom part of this page.
Randomness
Commonly, randomness
is understood as "pertaining to chance" (Parzen, Emanuel: Stochastic
Processes. 1962, p. 7). Another simple definition would be,
that a random event is one you don't know the result of.
Randomness plays a fundamental role in
many disciplines like
gaming, lottery, quantum physics, thermodynamics, statistics,
probability theory, information theory, biological evolution,
cryptography and even philosophy. Most of these domains use their own
definitions of randomness, because a useful universal definition is
still missing. Mainly, these definitions deal with
properties like:
-
unpredictability: a process can be unpredictable to one person,
even if it is predictable, because the person does not have enough
information about it. Other processes may not be predictable, because
our measures
are not good enough or the costs are too high. And at least there may
be also processes, that are not predictable at all, like it is assumed
in current
definitions of quantum mechanics.
-
independency: resulting values that were derived from a random
process must be independent from each other. E.g. when tossing a fair
(unbiased) coin
or throwing a fair dice, there are always the same probabilities
for
all possible outcomes of an experiment, and any realisation has no
meaning, effect or whatsoever to any other realisation.
-
non-determinism:
deterministic processes (fixed sequences of calculations, like
receipts) always lead to the same output for a given starting
condition. Such output is called pseudorandom and shares many
statistical characteristics with random sequences. Like all imitations,
pseudorandom sequences may be appropriate in some cases and as they are
simpler and faster to produce, pseudorandom numbers are widely used
today. In contrast, true randomness derives from random processes, that
are not describable deterministically.
As scientists still try to solve basic question like "does
randomness exist at all?" (determinism), today's definitions may be
subject to quite fundamental changes.
Computers and randomness
Computers are deterministic machines, so for one given input they
always produce the same output, or at least they follow an algorithm (a
receipt) to produce the output. At the end, the output is always
"signed" by this process. Examining the output reveals information
about by the structure of the internal code and hardware. Or in the
words of John von Neumann: "Anyone
who
considers arithmetical methods of producing random digits is, of
course, in a state of sin."
Bugs and randomness
Computers are designed to do exactly what they
are instructed to, otherwise we call it a bug. There are two kind of
bugs: software bugs and hardware failures. Unfortunately, you can't use
a software bug to invoke "some" randomness, because the bug would not
produce
random results. Even
if it looks like the bug produces random output, there must be a
structure
in it, because of the program code. In contrast, if a computer has a
hardware failure like a tottering contact on the main board, then this
could be a true random source. But in practice, the
computer most likely wouldn't be able to process anything else
correctly as well.
True randomness
So, to
generate
true random numbers, you need to have some kind of hardware
involved, that is a true random source. For example, you could make use
of a tottering contact in a custom built random output machine. Or you
could use a
radio, tune it to a frequency, where you can only hear white noise and
then feed this into the sound card of a computer and generate bits
based
on the input. The output of this is something a computer can not
calculate on his own. On the other side, hardware random number
generators are often sensitive to environmental influences like
temperature and humidity and may produce biased output under bad
conditions, so they tend to be more error-prone than software based
pseudorandom number generators.
Pseudorandomness
A Pseudorandom sequence looks random, but it is not. The elements
fo the sequence were
not obtained from random events, but from algorithmic calculations (a
deterministic process).
The better the quality of a pseudorandom number generator, the more
statistical random number tests it passes. There is a big range of
tests, like tests about the distribution
of values, the arithmetic mean
value and more specialised ones like the Chi-Square Test and the Autocorrelation
Test.
Local randomness is also an important property of a pseudorandom
string, because in many cases it is not acceptable, if the generator
pops out a "random" sequence of 1 Million '0's. Sure it is a valid
result from a theoretical viewpoint, but I am also sure, that the
gaming software industry is not interested in theoretical perfect
generators. In many applications you need a "more reliable"
randomness, when examined in local detail. In contrast, if you consider
a true random sequence of sufficient length
(consider millions or billions of numbers), there is a high probability
to have local areas, that do not look random and exhibit a pattern.
The predictability of pseudorandom number generators can be
especially useful for automated tests of software that has to handle
random input, because software tests are usually easier to interpret,
if they are repeatable.
Cryptographically secure
pseudorandom number
generators
As pseudorandom sequences are reproducible exactly and infinitely
by definition, computer scientists wanted to utilise the advantages of
pseudorandom number generators (working fast, being independent from
external sources of randomness and therefore also less error-prone,
because the inappropriate use of these sources can cause severe
non-randomness) and add "some" unpredictability, to generate
"cryptographically
strong" output sequences. You can find links to the
definitions of these concepts in the introducing part on top of this
page. In short, the definition of a cryptographically secure number
generator requires that it is hard to compute the output, even when
parts of the state of the generator are known.
The influence of
alphabet size and
string length on possible variations
If you generate a word that consists of 8 digits,
there are 100.000.000 possibilities to build an unique word. The
formula obviously reads simply as "<alphabet length> to the power
of <string length>". If you
just use a larger alphabet, like all Latin characters,
digits and some special characters - lets say you have 84 different
characters (like the default alphabet in my software) and stick to the
8 characters length - there are now already 2.478.758.911.082.496
possible
combinations. Taking 4 more
characters, so that the length of the string is 12 characters,
there are now even 123.410.307.017.276.100.000.000 possible words. You
see, the numbers are growing quickly when increasing any of the two
parameters, although the string length has more influence.
Proving randomness
How can you
prove, if something behaves random? In fact, you can't, as any possible
outcome is a valid random result, as we already mentioned before. See this nice
illustration for a better explanation.
However, here is an example: Before proving,
if a sequence is random, you may want to prove, if a single item of the
sequence is random, e.g.: Is 7 a random number? You see, this question
does not make sense at all. But if you go further and ask the
question for a specific sequence, e.g.: Is 723384 a random sequence?
Well, while this question does make sense now, it is not a trivial one
and you will get many different
answers. Ian
Craw, a mathematician, would answer something like: "Randomness is
not a property of individual numbers. More properly it is a property of
infinite sequences of numbers."
Mathematicians have an interesting approach to avoid questions
about the randomness of finite strings. They define, that a finite
sequence itself can not be called random, a random sequence must be
infinite, and this infinite sequence must contain every possible
subsequence for an infinite number of times. With this in our minds we
can now enjoy the following definition:
"An infinite random sequence is
infinitely-distributed,
in which any possible finite sub-sequence of numbers is uniformly
distributed." In practice, this means, that you can not
test, if a single sequence was derived from a random process, but if
you
take more and more sequences into account, the test results should
confirm your assumption more and more. But test results are to be
treated
with caution, because they can
only serve as indicators, but not as absolute measures for randomness.
Note, that you can not quantify randomness itself. A process is
either random or not, there is nothing in between. Thus, a sequence
derived from such a process therefore is also either random or not. But
you can test, as laid out before, if sequences appear more or less random in
specific aspects.
Statistical randomness
Statistics offers a plethora of random number tests,
to verify statistical randomness. As always, when using
statistical tools, you have to be very careful about how and what
questions
(hypotheses)
you ask, about where you get the data to test and about the conclusions
you make or try to make. I said, that it is
impossible to judge, if a sequence is random or not. Having
said that, I also have to admit, that statistical tests surely can help
a lot, when used properly. E.g. the mean value of one specific sequence
can be
any, it does not tell you anything about its randomness at this point.
But,
as you add more and more sequences to the tested sequence, the mean
value should slowly come nearer and nearer to the expected mean value
(the mean value of all possible numbers in that test). If this process
does not
manifest, you maybe found a hint about a certain non-randomness. You
could then do some further testing and eventually decide whether the
found hint indicates a correct assumption, or not.
With statistical methods, you almost never get answers like yes or
no, but answers like "with a probability of 95 % this is true". So, a
test may lead to the correct answer, but you can never be sure. Another
problem is, that it is not possible to compare values of different
tests. Thus, statistics offers helpful instruments to measure aspects
of
randomness, but is not an all in one solution. After testing a lot, you
may also state as Ian
Craw did: "If
you want to be thoroughly perverse you could argue that the fact that
it passes all such tests is itself evidence of a certain
non-randomness!"
But there are more
interesting approaches to test randomness:
Entropy and randomness
The concept of entropy, as it was developed in statistical
thermodynamics (entropy is associated to the amount of disorder in a
system, e.g. gas at room temperature is of high entropy, as its
molecules do not show any describable order), seems somewhat connected
to the concept of entropy in information theory, where entropy is a
measure for the amount of information, that a message contains (note
that the amount of information
does not say anything about its usefulness in this context). According
to the definition of information theory, a random sequence has maximum
possible entropy. In other words, this sequence contains so much
information, that you could not remove a single bit from it without
loosing information.
Compressibility and randomness
The concept of entropy soon led to other measures like the
Kolmogorov-Chaitin complexity in the algorithmic
information theory. Also
known as algorithmic entropy, descriptive complexity, Kolmogorov
complexity, program-size complexity or stochastic complexity, the
complexity
of an object is defined as the amount of information needed
to specify this object exactly. Consequently, a random object must be
of
high complexity, as there should be no way to describe the object any
shorter than in the way the described object does it. This directly
implies, that random objects must be incompressible. But you
also have to be careful when
testing on compressibility. Consider a substring of 1
Million '0's, taken from an infinite true random string. This is a
perfectly valid example of a substring, as it must appear in an
infinite random string. But this sequence - taken on its own - can be
compressed very
effectively, even if it was produced by a true random
process.
Examples of usage for the software
First, a few words of caution: never
use any software, that you do
not trust, especially
if security matters (e.g. to generate passwords).
I use the Pseudo Random String Generator to create passwords
for online services,
because those are most vulnerable to weak
passwords, especially when the password length is limited to 8 or
less characters. But again, I do not encourage
you to generate your personal passwords with my software, unless you
or somebody you trust, reads and understands the source code of the
application.
Generate random text to fill in "personal"
informations at suspicious websites/accounts is also helpful, as you
even reveal information about yourself, if you try to produce a random
string manually (you can't escape your own "circuits" and your
environment).
Create random looking
patterns/images of characters as works of art, backgrounds, or just for
the fun of it.
Play with Fortuna (with her cryptographically secure, algorithmic
and deterministic side, though :-)
Downloads and system
requirements
This is free
and open source software,
released under the MIT license,
so you can use the software however you like, if you don't forget to
cite the author and the license.
The current stable version is 1.1.0.9, released 2013-01-26.
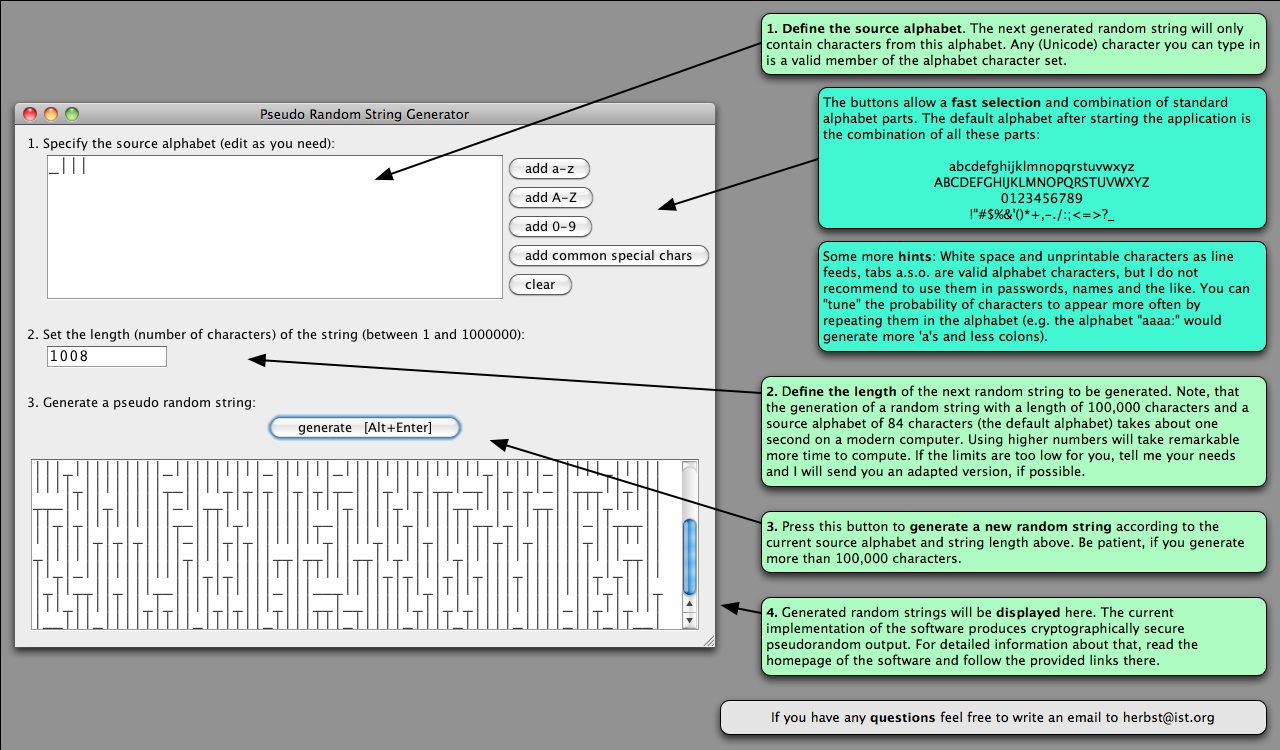
See a screenshot
including a brief introduction to the operation of the software.
Download the PseudoRandomStringGenerator
(197 KB) for Microsoft Windows XP / Vista / 7 / 8. This version
needs the Java 6 Runtime (or newer)
installed.
Alternatively you can download a standalone and portable version of the
PseudoRandomStringGenerator
(17 MB) with an included Java 6 Runtime.
Download the PseudoRandomStringGenerator
(406 KB) for Apple Mac OS X 10.5 (64-bit Intel only) / 10.6 / 10.7
/ 10.8.
Mac OS X 10.5 and 10.6 usually has the Java 6 Runtime installed. If
not, it is
available under System Preferences > Software Update. Mac OS X 10.7
and 10.8 does not
include the Java 6 Runtime, but if it is needed, a dialog will pop up
and
ask if Java should be downloaded and installed.
Download the PseudoRandomStringGenerator
(147 KB) for Linux / Unix. The
software should run on all operating systems that have the Java 6 Runtime (or newer) installed).
Contact and support
If you have any questions or need support, send a mail to the
address mentioned in the copyright notice at the bottom of this page.
Random links
-
kolmogorov.com -
homepage of Andrei Nikolaevich Kolmogorov, who was an important
mathematician. He surely would deserve a more decent homepage though.
-
-
umcs.maine.edu/~chaitin
- homepage of Gregory J. Chaitin, containing most of his work. He is a
mathematician, computer scientist and philosopher, contributing a lot
to
algorithmic information theory and mathematics,
with a bias towards topics like limits, paradoxes, randomness,
incompleteness and unprovability. Books: Exploring
Randomness, Information,
Randomness & Incompleteness, The
Unknowable, The Limits Of
Mathematics.
-
jucs.org - a brief
introduction into (pseudo)random number generators by Makoto Matsumoto
et al. "Pseudorandom
Number Generation: Impossibility and Compromise" Journal of
Universal Computer Science, Vol. 12, No. 6 (2006), 677-679.
-
cg.scs.carleton.ca/~luc
- a quite extensive link list to random number generation by Luc
Devroye.
-
cs.auckland.ac.nz/~pgut001
- homepage of Peter Gutmann, a "Professional Paranoid" and thus also
dealing a lot with random numbers.
-
cwi.nl/~paulv -
a paper by
Paul M.B. Vitanyi providing an elaborate introduction into many aspects
of randomness.
-
cs.berkeley.edu/~daw
- David Wagner's links to randomness for cryptography.
-
random.mat.sbg.ac.at
- about random number generators, maintained by mathematicians and
computer scientists at the Department of Mathematics of the University
of Salzburg.
-
-
random.org - a true random
number service that generates randomness via atmospheric noise.
-
ciphersbyritter.com
- Ciphers By Ritter/Ritter Labs by Terry Ritter, offering information
on novel encryption technology (including randomness).
-
-
mindprod.com - Java-related
information and links about random numbers,
located in the often helpful Java
& Internet Glossary of Roedy Green's remarkable homepage.
-
-
-
statpages.org - an
extensive collection of links to
free accessible statistical software, online tools, books, manuals,
demos, tutorials
and related resources with basic descriptions about the linked web
pages.
-
r-project.org - a free,
open source, multi-platform and widely used standard software for
statistical computing. Another good resource to it is the R Programming
Wikibook.
-
ent - a
pseudorandom number sequence test program. The website also has a nice "Introduction
to Probability and Statistics" including some online calculators.
-
Diehard tests - a battery of statistical random number tests:
the original Diehard
Battery of Tests of Randomness by George Marsaglia and Dieharder:
A Random Number Test Suite by Robert G. Brown, which is meant to be
a cleaned up version of the original, additionally incorporating the
tests from the Statistical
Test Suite (STS) developed by the National Institute for Standards
and Technology (NIST).
-
-
Online
calculators (chi-square tests of goodness of fit and independence,
correlation test for independent correlation coefficients and more...)
provided by Kristopher J. Preacher.
-
bjurke.net - an
online pseudorandom string generator from Benjamin Jurke showing some
statistical test values about the distribution and entropy of the
generated strings.
Pseudo Random String
Generator: Copyright (c) 2011 René Herbst (herbst[at]ist.org)
{kind=link}